編輯校對
為確保數據庫的資料齊備和准確性,整個制作過程需要有系統地和足夠人手去完成繁復的編輯和校對工作。
數據庫資料的編輯和校對工作,除了承辦制作機構的努力外,更得到多家機構和單位的鼎力支持和協助。
編輯校對單位
| 上海人民出版社 |
編審校對 |
| 上海師范大學圖書館 |
原書圖像校對 |
| 北京圖書館 |
卷內標題檢索校對 |
| 遼寧省圖書館 |
卷內標題檢索校對 |
| 東北大學等多位教授、研究生 |
卷內標題檢索校對 |
| 北京大學文史系研究生 |
卷內標題檢索校對 |
整個編校隊伍超過二百人,在兩年的時間內,將一百六十五張數據光碟進行瀏覽,解決對書籍位置的核准、書名的確定、著者與編纂者的調整、書名與著者名的對應等各項工作。雖然電腦能輔助校對工作,但要從各個角落,用多種方法對照原文,快速而正確地校對與補充輸入,其難度可想而知。
經過多次校對,目前各數據庫沿用的凡例部分如下:
- 全文文本數據
- 原文真跡圖像數據
- 書名數據
- 著者數據
- 輔助數據 (分類條件、聯機字典、漢字關聯、輔助輸入、輔助工具)
|
 |
1. 全文文本數據
《四庫全書》是在清代乾隆年間編纂,歷時十載,由3,000餘名抄繕書手謄寫,是我國迄今為止最大的一部叢書。全書文字總數共七億多字次,其中漢字出現逾七億字次。
為了盡量准確地表達這些漢字,本電子版采用了世界上迄今為止最大的國際標准編碼字符集
ISO/IEC 10646-1:2000 中的CJK標准漢字27,000餘個 ( CJK Unified Ideographs
和CJK Unified Ideographs Extension A ),並且在該標准框架內的Private Use
Area 區域內定義了近5,000個在古籍中較常使用的漢字,共計32,000編碼漢字。我們把這個漢字字符集稱作CJK+。根據統計,「四庫全書電子版」的漢字數量、漢字出現字次,在CJK+中的分布分別為:
| 字類 |
字數 |
字次數 |
| 數量 |
百分比(%) |
數量 |
萬分比(%%) |
內
字 |
CJK |
18670 |
63.99 |
695233305 |
9925.02 |
| CJK_A |
6144 |
21.06 |
2522469 |
36.01 |
| EUDC |
4296 |
14.73 |
1959813 |
27.98 |
其它
符號 |
38 |
0.13 |
455653 |
6.50 |
| |
外字 |
24 |
0.08 |
314388 |
4.49 |
| |
總數 |
29172 |
100 |
700485628 |
10000 |
CJK+ / EUDC(Private Use區域)的自定義漢字,主要從以下來源選取:
- 上海人民出版社《中華古漢語字典》中的漢字(全選)
- 《四庫全書》作者數據庫中的全部漢字(全選)
- 《四庫全書》書名數據庫中的全部漢字(全選)
- 《四庫全書》180萬條篇目(全選)
- 《四庫全書》中出現率在3次/億以上的漢字
- 《中華文化通志》中的漢字。
在CJK+的基礎上,我們為電子版製作了新舊兩套筆形的楷體字庫、開發了OCR手寫漢字識別引擎、校對軟件以及鍵盤輸入方法─四庫流行碼。
盡管如此,由於《四庫全書》涵蓋內容之大和手抄本字體的變異之鉅,偌大的字符集仍然不可能
100%地保持原書字跡的真貌。因此,在工程實際中,我們採用了一整套規則。
規則的目的是在現有CJK+字符集的基礎上盡量保真。不做以簡代繁,只做有控制的異體代換。異體代換之寬嚴在不同情況下有所不同:字書從嚴,其他從寬﹔字頭從嚴,釋義從寬﹔表形時從嚴,表義時從寬。在異體代換時根據文字的一些具體情況實行了不同處理,其原則如下:
(一)異體字及外字的處理
| 1. |
保真轉換:
凡原書字跡與CJK+字形一致時,不論是正體或異體,均實施對應的保真轉換
- 用編碼漢字表示。
|
| |
| 2. |
有控制的異體代換:
字符集中沒有、但在《四庫全書》中出現的異寫/異體漢字,已盡量選用字符集中與之最接近者代換(即:用微小筆形變異的同字代換),例如:
"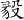 "代換為"毅" "代換為"毅"
|
| |
| 3. |
對《四庫全書》抄寫過程中出現的增筆、減筆、誤筆及書寫習慣而出現的明顯訛誤,校對過程中已依照文意做辨別處理,例如:
"剌史"改為"刺史"。
|
| |
| 4. |
《四庫全書》中避諱字很多,不僅獨體字避諱,寫成缺筆,而且由這些字為構字部件組成的合體字同樣避諱,例如:
"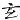 "、" "、"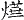 "、" "、"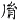 "、" "、"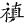 "、" "、"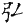 "、" "、"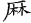 "、" "、"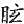 "、" "、"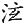 "、" "、"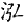 "、" "、"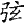 "為了尊重古籍原貌,保留其文化現象,則在字符集用戶擴充區造字做到保真轉換。但是通過漢字關聯技術,從正字也可檢索到避諱字。 "為了尊重古籍原貌,保留其文化現象,則在字符集用戶擴充區造字做到保真轉換。但是通過漢字關聯技術,從正字也可檢索到避諱字。
|
| |
| 5. |
對於《四庫全書》原書中發現的疑難模糊之處("模糊字"),已盡力參照原書和工具書加以鑒別,實在難以辨別者,保留其原圖形作"□"處理並加以說明。閱讀時,打開聯機字典,當光標移到□處時,會自動出現原文字跡。例如:
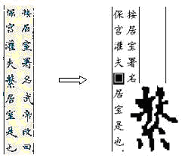
|
| |
| 6. |
外字處理方式:
《四庫全書》中出現了許多外字(即:無法按照原形保真轉換,又無法進行異體代換的字)我們採用了以漢字結構符等特殊標記開頭的字符串來表示它。以下將它如何顯示、檢索、提示、聯機字典等的幾個方面詳細說明: |
| |
| |
| 字串 |
字串含義 |
顯示 |
檢索 |
提示(鼠標移到該字時的反應) |
聯機字典(鼠標單擊該字時的反應) |
實例 |
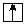 |
倒立字 |
顯示倒立字 |
可檢索,以正常字檢索 |
無 |
給出正常字的拼音及釋義 |
 |
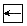 |
左旋轉字 |
顯示左旋轉字 |
可檢索,以正常字檢索 |
無 |
給出正常字的拼音及釋義 |
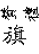 |
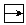 |
右旋轉字 |
顯示右旋轉字 |
可檢索,以正常字檢索 |
無 |
給出正常字的拼音及釋義 |
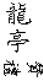 |
| ⊙ |
有圈包含此字 |
|
可檢索,以正常字檢索 |
無 |
給出正常字的拼音及釋義 |
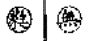 |
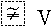 |
相似而不等如:增筆、減筆等。 |
顯示正常字 |
可檢索,以 後面的v檢索 後面的v檢索 |
給出原字跡圖 |
給出異體字的釋義 |
 |
|
| |
| |
|
|
|
|
|
|
| |
是未編碼的漢字,其結構如開頭字符所描述的。 |
顯示結構符 |
可檢索,以結構符檢索 |
給出原字跡圖 |
無 |
|
結構符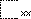 |
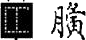 |
 |
 |
 |
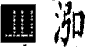 |
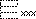 |
 |
 |
 |
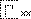 |
 |
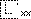 |
無實例 |
 |
 |
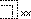 |
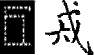 |
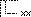 |
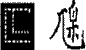 |
|
(二)版面問題處理原則
| 1. |
卷首做圖形處理。 |
| |
| 2. |
卷尾印章(乾隆御覽之寶):刪除。 |
| |
| 3. |
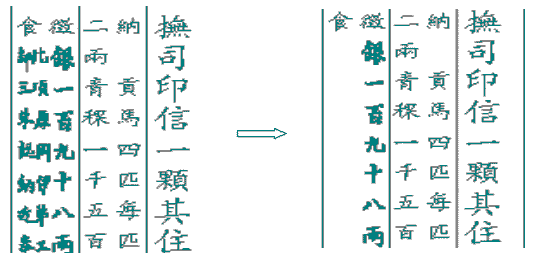
緊密字列:長於30字的列由於字位過密無法顯示而將其刪除,只保留列中重要內容(人名或重要的大字內容)。 |
| |
| 4. |
易類、八卦符下的八卦卦名,由原書豎向大字改為橫向小字。 |
| |
例:
5. 極個別類表格式的緊密字列刪除較長列的部份字,以使整頁字正常顯示。
6. 極個別單列小字和單列小小字保留,雙列小小字刪除。
(三)特例情況
小學類中的字書和韻書,大多數是以保存或辨析字形為目的,這些書中的字形包括了歷代積累下來的異寫字、辨析字、訛誤字、避諱缺筆字,以及由於手抄典籍所造成的字形差異,遂使漢字字形的數量非常龐大,是迄今為止的任何一種標準字符集所無法容納的,這就使得小學類古籍在轉換成電子版本時,不可能完全用編碼漢字保真,而只能在現有字庫所能支持的範圍內,最大限度地保留它們的原貌。
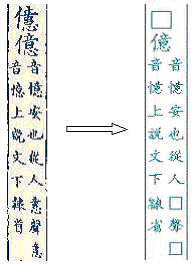
| 1. |
存形、辨形的字書,不作代換。其目的在於保留當時的手字形,
辨析字形之間的差異,如《九經字樣》、《干祿字書》。 例如: |
 |
 |
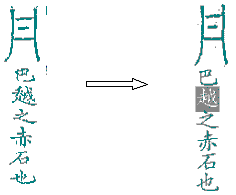
| 2. |
釋讀性字書或存義的字書,為了便於檢索,已作部份代換。如《歷代鐘鼎彝器款識法帖》中有一些章頁是用現今文字去轉寫古文字的,目的在於幫助今人認讀古文字的,而不是為了保存古字形。例如: |
| |
 |
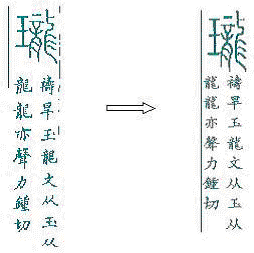
| 3. |
解釋音義時適當代換,分析形體時保留原貌。
例如: |
| |
 |
| 4. |
散見時適當代換,對比時保留原貌。 例如: |
| |
 |
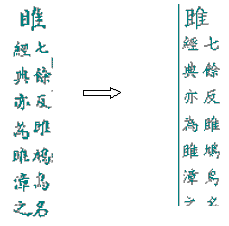
| 5. |
非抄寫訛誤一般不做勘誤處理。
例如: |
| |
 |
(四)質量指標
經過多方面的努力,除了原文極少數的模糊字以及集中在小學類的極少數外字(這些外字的解決,有待ISO/IEC 10646- Part 2的制定和頒布)之外,全書漢字的99.955%的都已經用編碼漢字表示,併可進行檢索。外字和模糊字數量為314,388字次,佔全書4.49%%﹔其中小學類174,202字次,佔全書2.49%%﹔
非小學類140,186字次,僅佔全書2.00%%。
經過國家圖書館善本部專家抽測,文本的錯誤率為 :
經部: 0.756%%(抽檢字量1,931,023)
史部: 0.590%%(抽檢字量1,033,914)
子部: 0.547%%(抽檢字量657,172)
集部: 0.100%%(抽檢字量4,120,351)
大大低於萬分之一的國家標准。
《四庫全書》涉及的內容極為廣泛,收錄的文獻典籍浩如煙海,其中許多字跡、字體繁雜不清,許多字形發生變異,難以辨認,這給錄校工作帶來很大困難,我們組織了一支以專家學者為主的古漢語隊伍,對《四庫全書》中的疑難文字進行了分類甄別,在各部門及廣大校錄員共同努力下,終於將這篇宏偉巨作--《四庫全書》電子版奉獻給世人。由於工程浩大,時間短,難免出現缺點、錯誤,敬請廣大讀者和專家批評指正,以便以後再版時修訂。
1. 原文真跡圖像數據
「全文版」的原文圖像即「標題版」的圖像,以《景印文淵閣四庫全書》為底本,以電腦高速掃描,以300DPI的圖像方式儲存。原文圖像經過頁面切分,將一個影印頁切分為兩個原始頁,以便在顯示屏幕下能將單幅原始頁清晰顯示出來。
《四庫全書》原書存在諸如頁碼、書名、卷數等方面的錯誤。為保持原書面貌,我們在訛誤處旁加入更正標志符。當您遇到此類標誌時,需用光標點擊該標誌,即可看到我們的更正。同時,我們還以(Y:)注明原書誤寫的卷次、頁碼,以便用戶查找原文。例如,原書將〝卷一百十六〞誤寫為〝卷一百六十六〞,我們改正為〝卷一百十六(Y:卷一百六十六)〞。
2. 書名數據
書名大致依照《景印文淵閣四庫全書目錄索引》,個別書名按原書情況有所改動。各書名並按原書順序排列。
3. 著者數據
「全文版」共收著者二千七百七十七人,著者詳細資料包括著者姓名、字、號、 號等,並在產品檢索結果的顯示欄內通過選擇模式顯示。
| 1. |
凡《四庫全書》正文頁有明確撰者名、著者名、補者名、考証者名、編輯者名的,悉數收入﹔正文頁沒有列出,而提要中明確提到的,亦均收入﹔提要中所給不確定者,均查閱其他相關資料予以確定併收入﹔提要注明不詳,而且至今未有定論者,均注"不詳"﹔對無其他資料可証的,均注為"不著姓名"﹔御制、御纂、御定、欽定、奉敕修纂、御覽一類的圖書,一般 收總編纂官姓名,併於編修人名後括號內署"官修"字樣。 |
| |
|
| 2. |
對有著作的歷代皇帝,為求統一著者姓名,凡原書用年號者一律改為皇帝本名,併以括號顯示其雙名,括號外的是皇帝的本名,括號內則是皇帝的廟號或 號。如:李世民(唐太宗)、朱元璋(明太祖)﹔"康熙"改為"愛新覺羅玄燁(清聖祖)"、"雍正"改為"愛新覺羅胤 (清世宗)"、"乾隆"改為"愛新覺羅弘歷(清高宗)"等。 |
| |
|
| 3. |
若著者為釋氏,檢索時釋字加在法號前。 |
| |
|
| 4. |
凡書名前所冠"欽定"、"御定"、"御制"、"御纂"等字樣,均予保留,如《欽定八旗通志》、《御定康熙字典》、《御制滿珠蒙古漢字三合切音清文鑒》。 |
4. 輔助數據
4.1 分類條件
完全依據《四庫全書》的分類製作而成。
1. 四庫分經、史、子、集四部,每部分類,類下有屬,屬下即書名,共四十四類、七十屬。
2. 書名數據共收書目三千七百二十七條,附錄之書,有單行性質與獨立名稱,則於書名下單列條目,如:四書章句集注、四書章句集注__大學章句、四書章句集注__論語集注、四書章句集注__孟子集注、四書章句集注__中庸章句。
4.2 聯機字典
| |
用戶在檢索或閱讀《四庫全書》的時候,若遇到文字方面的問題,可隨時查閱聯機字典。如果想查閱書籍的詳細資料,則可查閱《四庫大辭典》。 |
| |
|
| 1. |
本產品中的聯機字典的素材,取自上海人民出版社1997年8月出版的《中華古漢語字典》的字音字義﹔爾後,又根據《四庫全書》的用字以及《中華文化通志》的用字,補充了約5千字的信息。 |
| |
|
| 2. |
《四庫大辭典》原為吉林大學出版社1996年1月出版。本電子書僅將書名和著者名從簡體字換成繁體字,其餘文字仍用簡體字。本電子書利用該書資料建立了大量的超鏈接(Hyperlink),反映了諸多著者與著者、著者與書名、書名與書名的內在聯系,以方便用戶的研究工作。在測試過程中我們也發現《四庫大辭典》有不少錯誤,限於條件未予更正,請用戶查看時注意。 |
4.3 漢字關聯
《四庫全書》有很多異寫字,為了提高檢索的命中率,本電子書設計了漢字關聯功能,即是將輸入的字串據簡繁、正異、古今、通假、新舊字形等關系衍生成一系列字符串,經全部選擇或局部選擇之後進行檢索。用戶如需要,可以打開此功能。
4.4 輔助輸入
為了在非中文平台上輸入漢字,我們提供了輔助輸入,用戶可根據字的總筆划數及部首選擇所需漢字。
4.5 書名瀏覽和著者瀏覽
| 1. |
新筆形: 部首以四川、湖北辭書出版社1986年10月出版的《漢語大字典》為依據。 |
| |
|
| 2. |
傳統筆形(舊筆形): 主要以中華書局1958年1月出版的《康熙字典》的筆劃、部首為依據,再統一規範劃數。只統一字的體例,不作大的改動。有的字《康熙字典》本身筆劃不統一,則取其數眾或符合今人習慣者。如"垂",《康熙字典》 既入八劃又入九劃,取八劃。又如"路",《康熙字典》入十二劃,今改入十三劃。遇有缺筆者,適當予以補齊,如"泫"。《康熙字典》中有些字樣與今人習用的相去甚遠,如"興",則字樣及筆劃從今。新舊字形或簡繁字體的筆劃、部首不一致時,以習用的筆劃為准。 |
| |
|
| 3. |
拼音: 按英文字母排序。拼音中的yu音,以v代替,例如"呂",即以lv來檢索。
使用拼音排序時,若屬於十三個零聲母拼音,請先在「選擇書名/姓氏首字起始拼音」欄選擇a、e或o,再在「選擇書名/姓氏首字韻母」選擇相關聯的韻母,
然後按「確定」鍵。 |
| |
|
| 4. |
注音: 主要依聲、韻母排序。 |
| |
|
| 5. |
朝代:依據著者的朝代來選取著者。 |
4.6 輔助工具
| 1. |
文淵閣《四庫全書》簡明目錄 |
| |
|
| 2. |
《四庫大辭典》(吉林大學出版社出版) |
| |
|
| 3. |
《中華古漢語字典》(上海人民出版社出版),內附由清華大學計算機系研製的單字發音系統 |
| |
|
| 4. |
古今紀年換算,主要參考1979年上海辭書出版社出版的《辭海》(縮印本)附錄
"中國歷史紀年表"。 |
| |
|
| 5. |
干支/公元年換算 |
| |
|
| 6. |
八卦.六十四卦表,主要參考1982年安子介《學習漢語》(Cracking
Chinese Puzzles)一書中的Significance of Bagua Characters。 |
|